例えば問題集で、下のようにスペースを使わないほうがいいです。
スペースの幅は一定していないので、整合性を失います。

文頭は、インデントを使います。
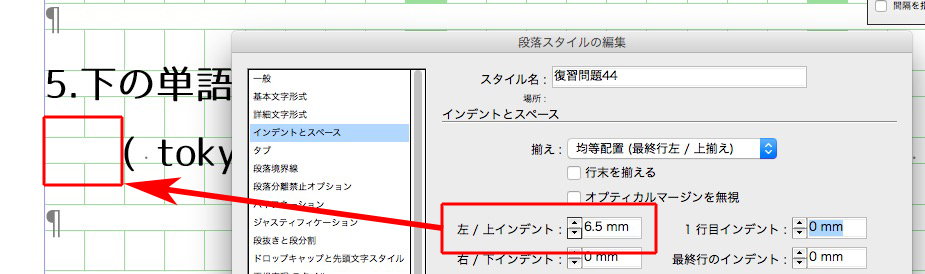
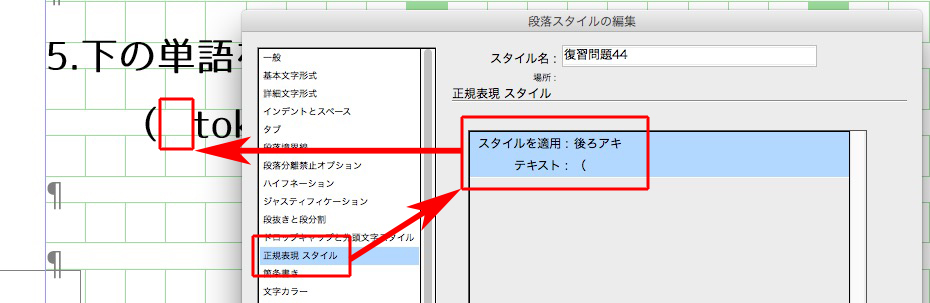
前かっこ( の後ろを空けるには、正規表現スタイルを使います。
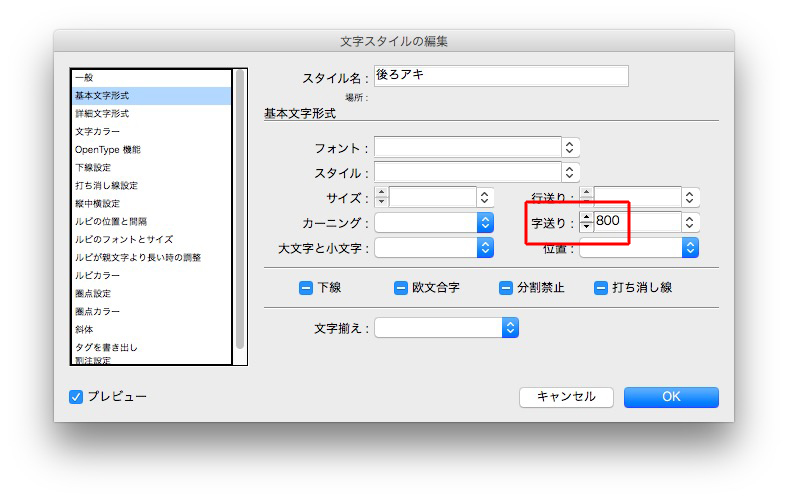
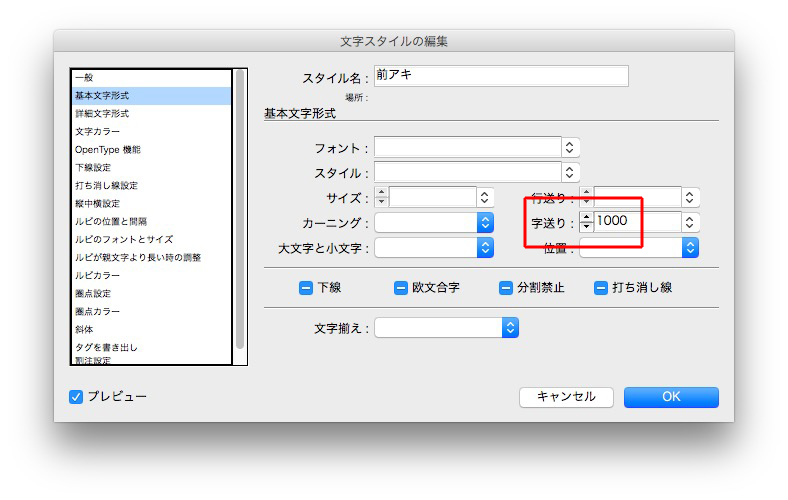
文字スタイル「後ろアキ」の設定は、
カンマ「,」の後ろのアキは、
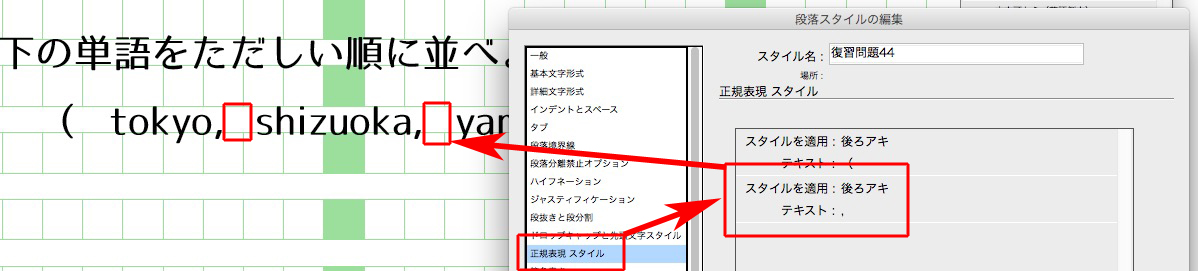
後ろかっこ )の前のアキは、
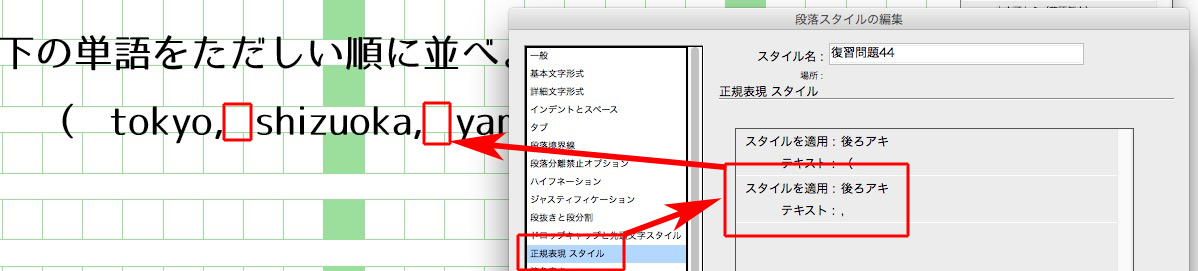
文字スタイルの設定は、
段落スタイルが完成しました。

正規表現は見よう見まね
例えば問題集で、下のようにスペースを使わないほうがいいです。
スペースの幅は一定していないので、整合性を失います。
文頭は、インデントを使います。
前かっこ( の後ろを空けるには、正規表現スタイルを使います。
文字スタイル「後ろアキ」の設定は、
カンマ「,」の後ろのアキは、
後ろかっこ )の前のアキは、
文字スタイルの設定は、
段落スタイルが完成しました。
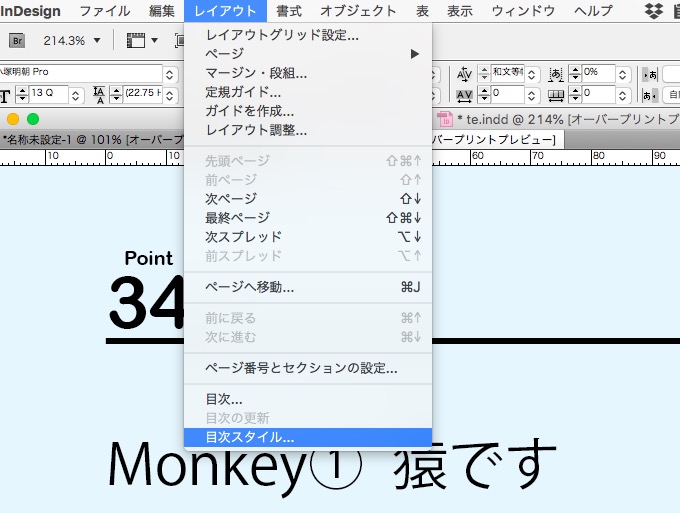
目次を作ります。
下のレイアウトは、ひとつのテキストボックスに入っています。

目次スタイルを開きます。
「新規」をクリック。
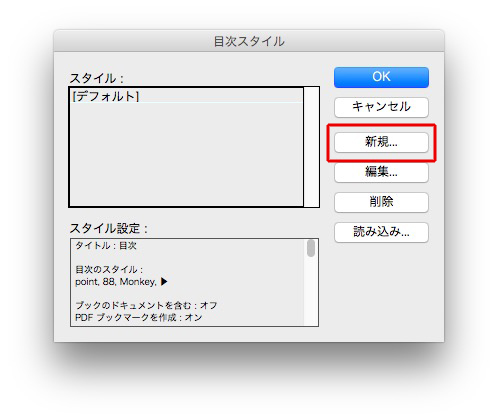
ここでは、目次のスタイルだけ指定して閉じます。

「目次」を開きます。
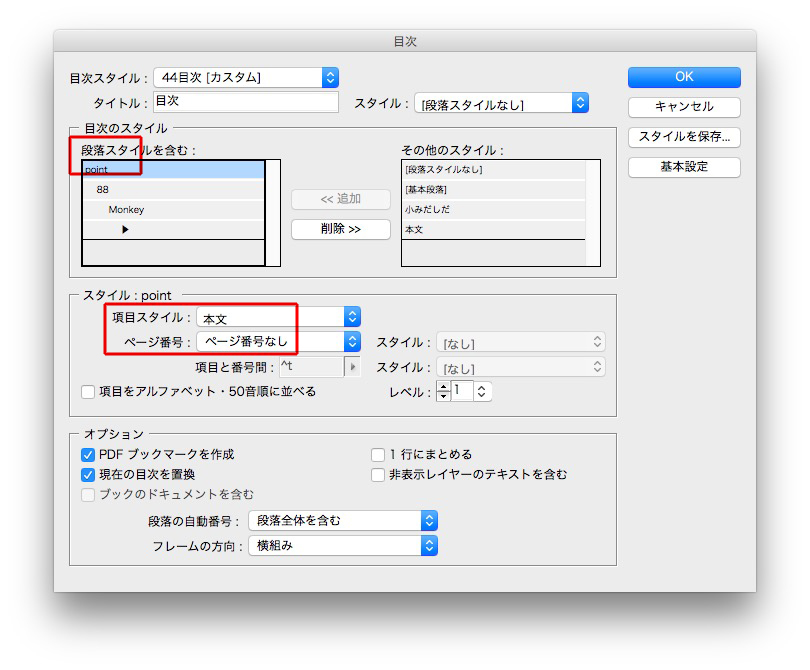
それぞれ、指定します。
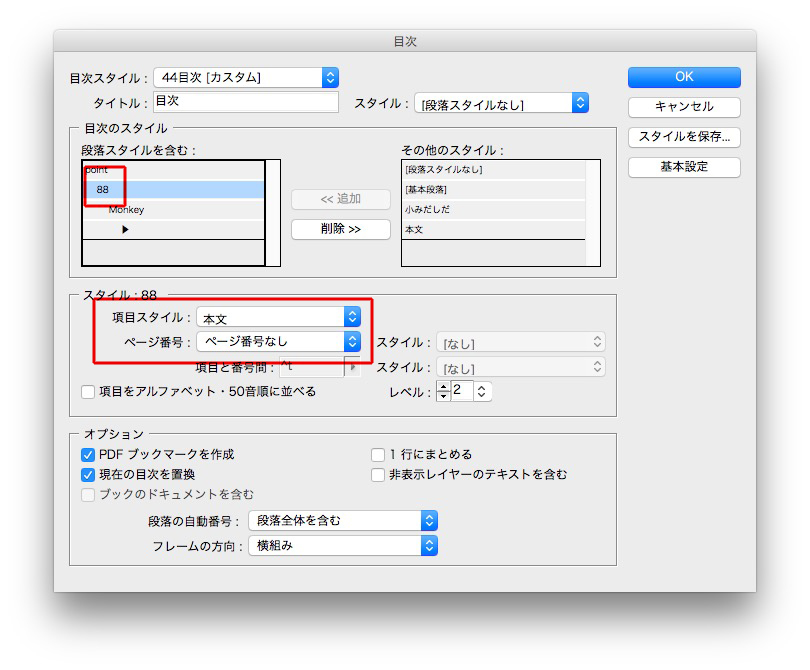
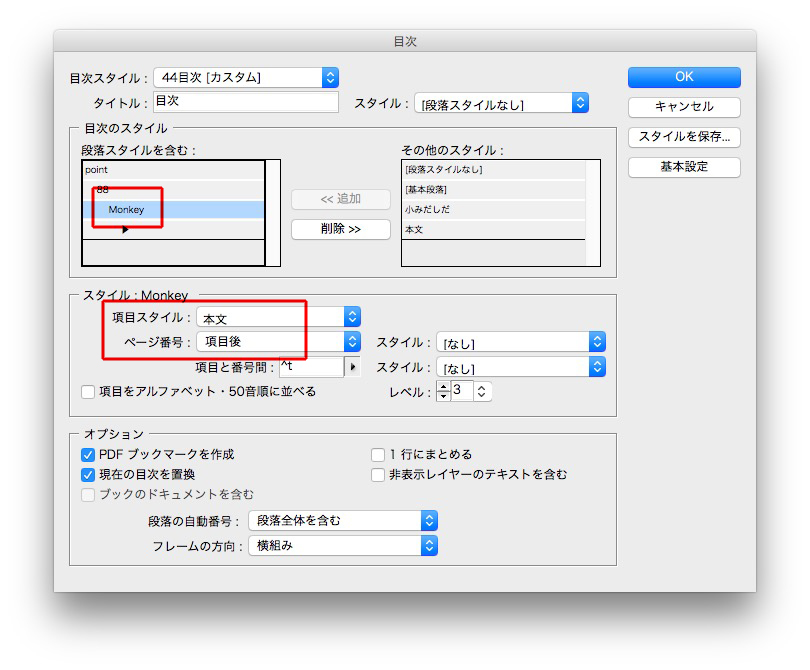
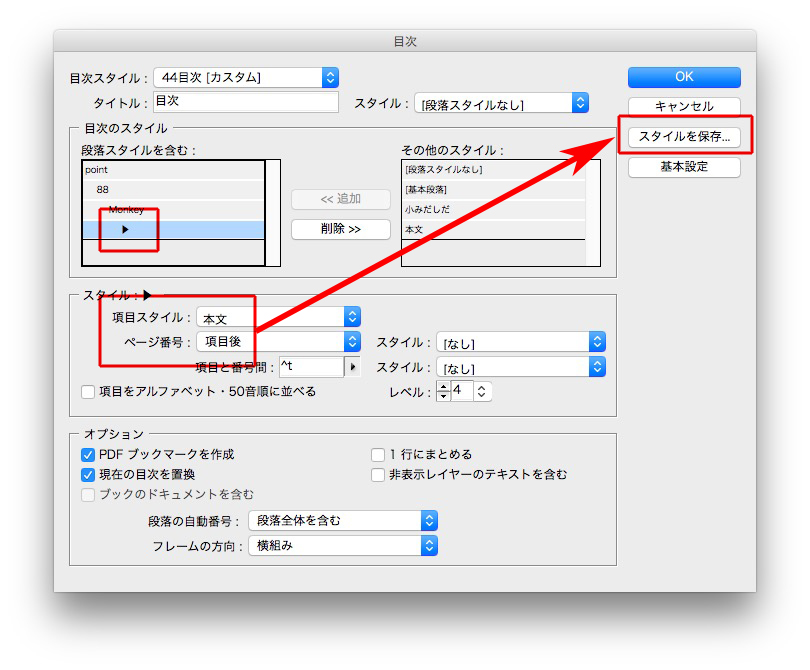
OKをクリックします。
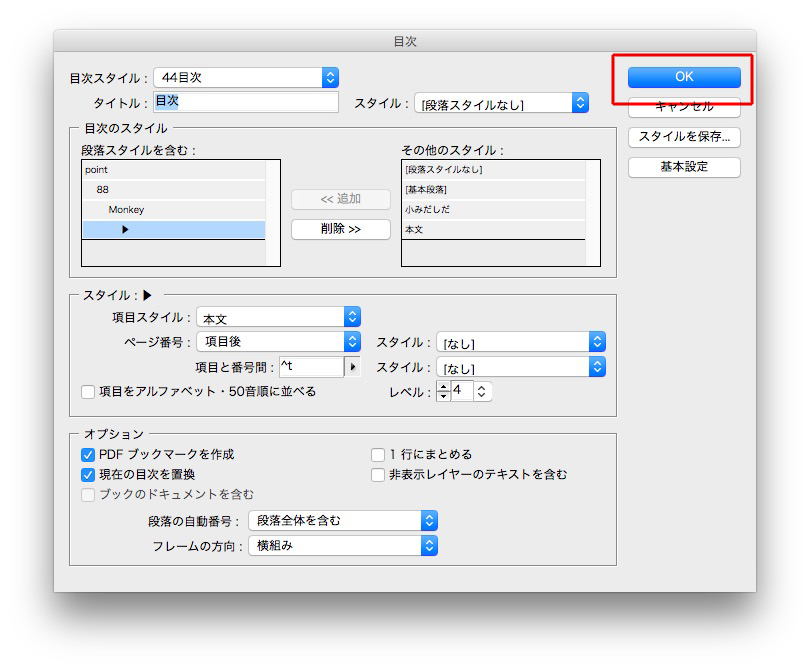
これが、作成された目次原稿です。

検索と置換で、不要な改行をタブに変えます。
検索文字列 → (Point)\d(\d.+)\d(.+?)
置換文字列 → $1\t$2\t$3
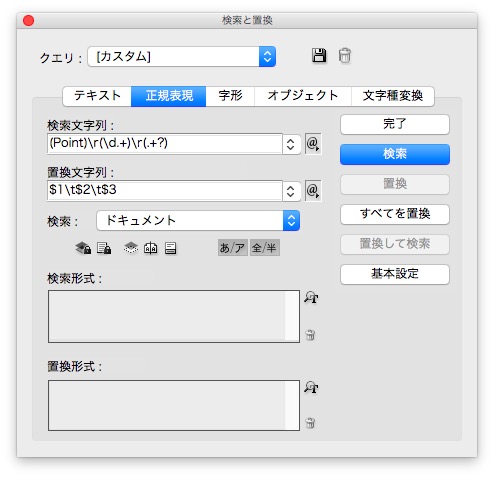
改行を減らし、タブが入りました。

もし目次のデザインが決まっているならば、それぞれの項目スタイルを指示して
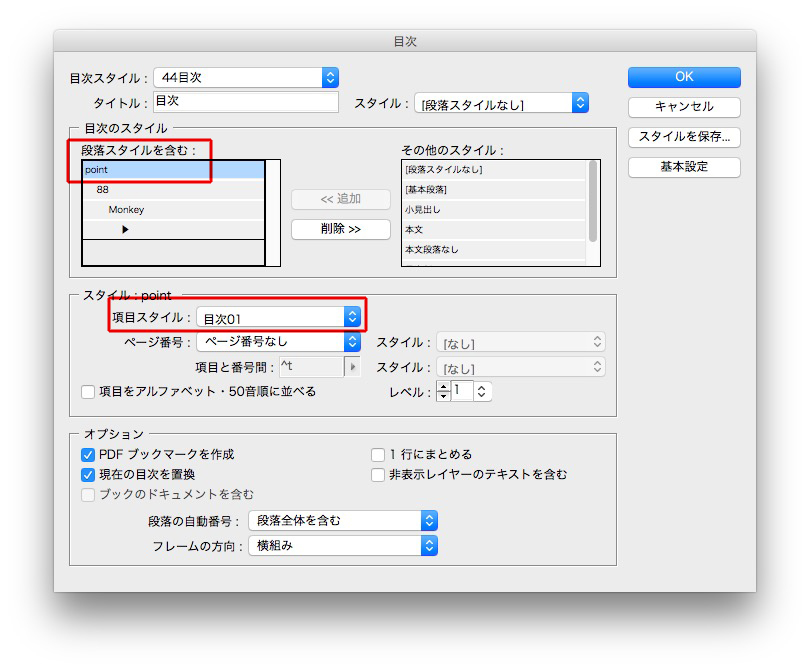
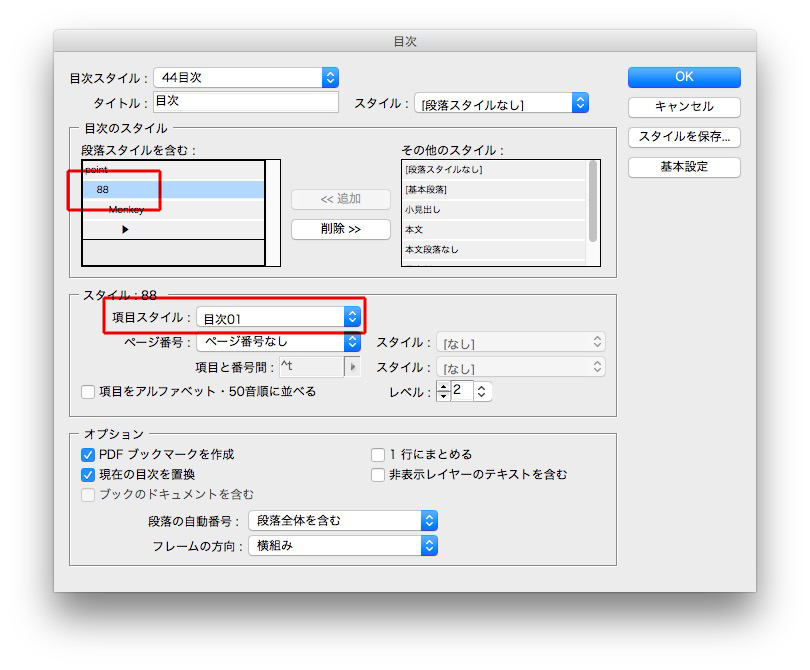
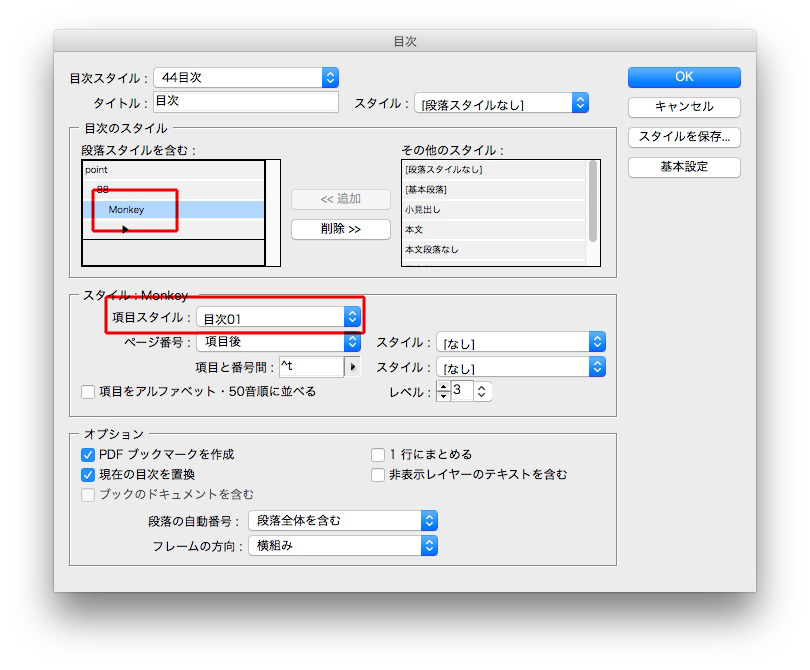
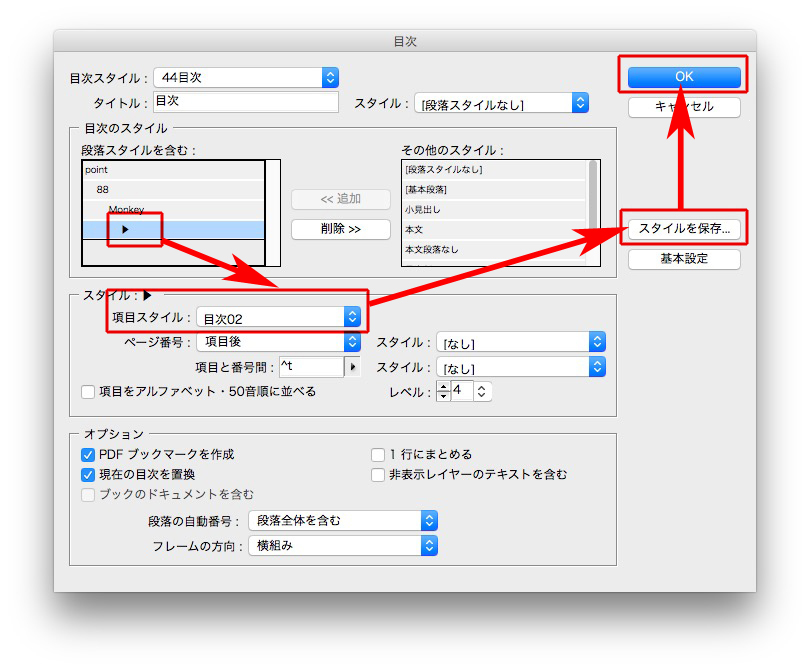
一気に目次が仕上がります。

記事「」の枠をオブジェクトにします。
「大見出し」の複製を作ります。
複製では、段落境界線のチェックを外します。
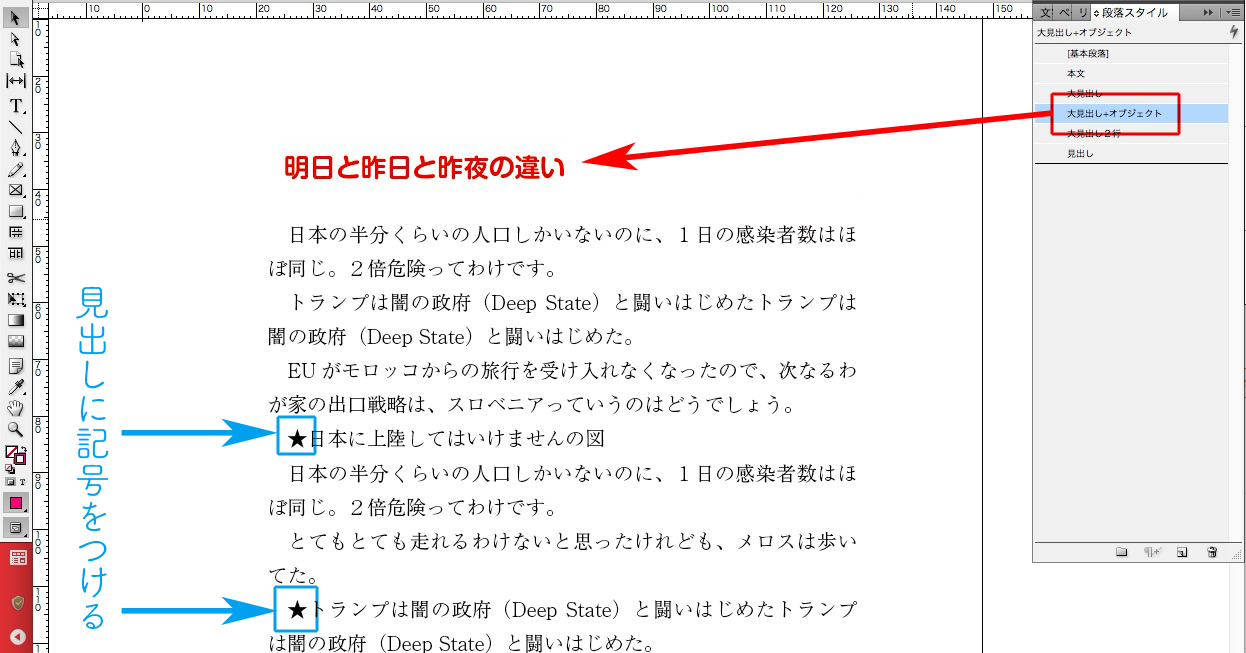
飾りの枠を作ります。

罫線と枠をグループ化してから、正しい位置に配置します。

オブジェクトスタイルを作ります。
とりあえず、オブジェクトスタイルの基本属性は、「アンカー付きオブジェクトオプション」だけにします。
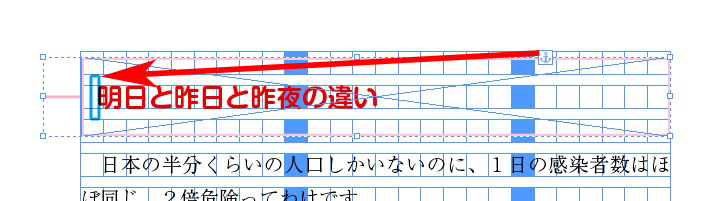
見出しの文頭に、アンカーを付けます。
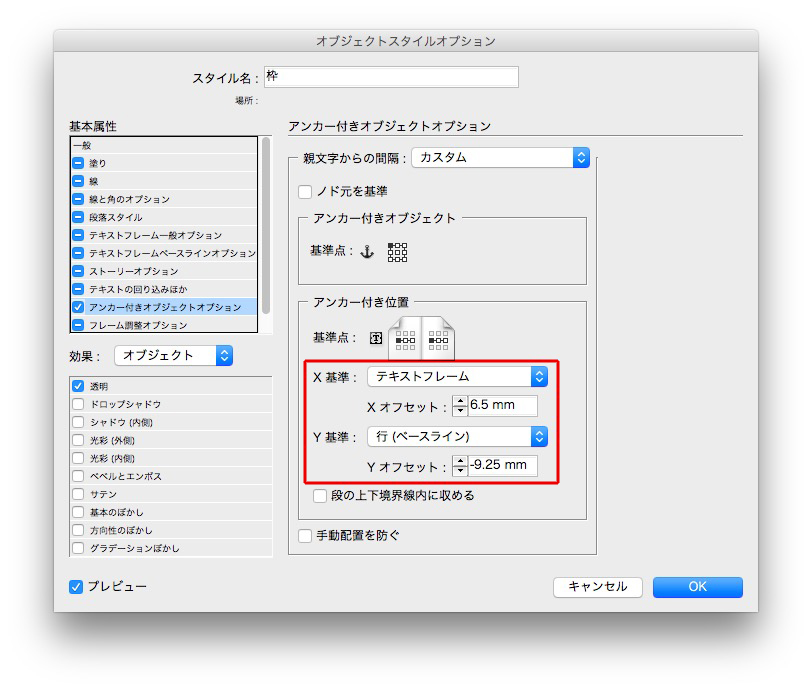
「アンカー付きオブジェクトスタイル」は「カスタム」にします。
「アンカー付き位置」を調整します。
オブジェクトをコピーしてから、検索と置換をします。
検索文字列 → ^★
置換文字列 → ~c
置換形式 → 段落スタイル
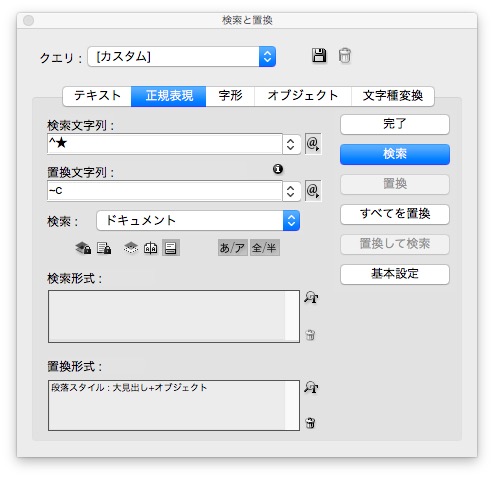
見出しに段落スタイルがあたりました。
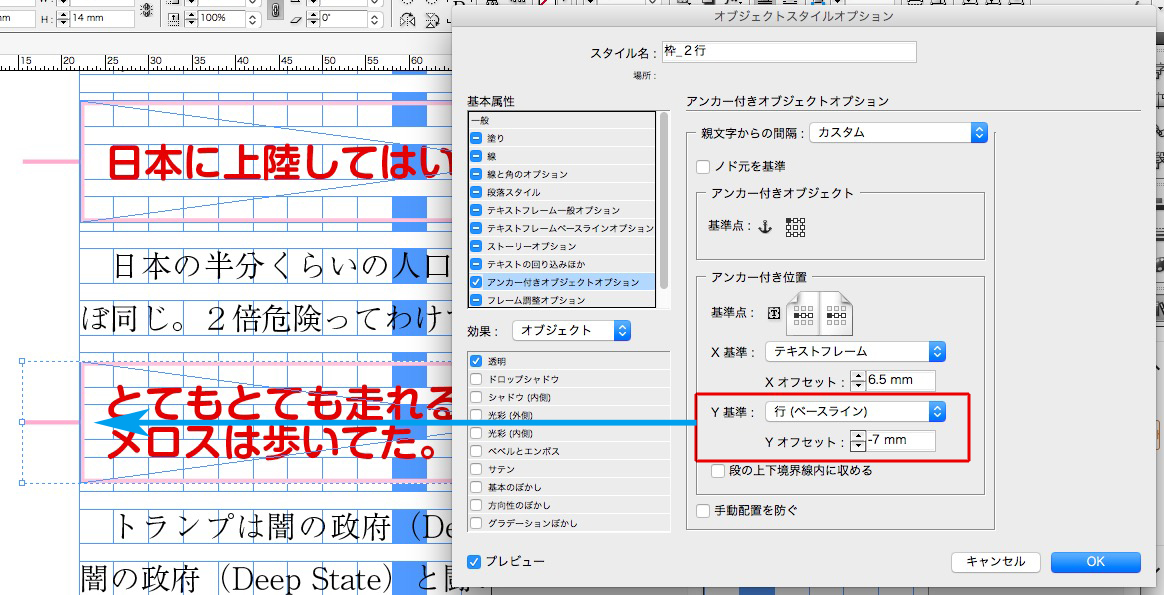
しかし、2行見出しではデザインが崩れています。

オブジェクトスタイル「枠」を複製します。
「アンカー付き位置」を調整します。
以降の2行の見出しは、目視で手動でオブジェクトスタイルをあてます。

例えば、見出しの頭に「●」があるとき、

検索と置換で、
検索文字列 → ^(●)
置換文字列 → $1─
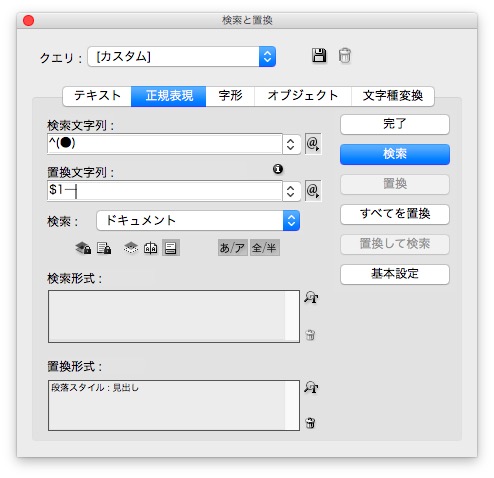
段落スタイルがあたりました。
見出しの前に1行アキを入れました。

見出しの前の1行アキは、「段落前のアキ」で調整します。
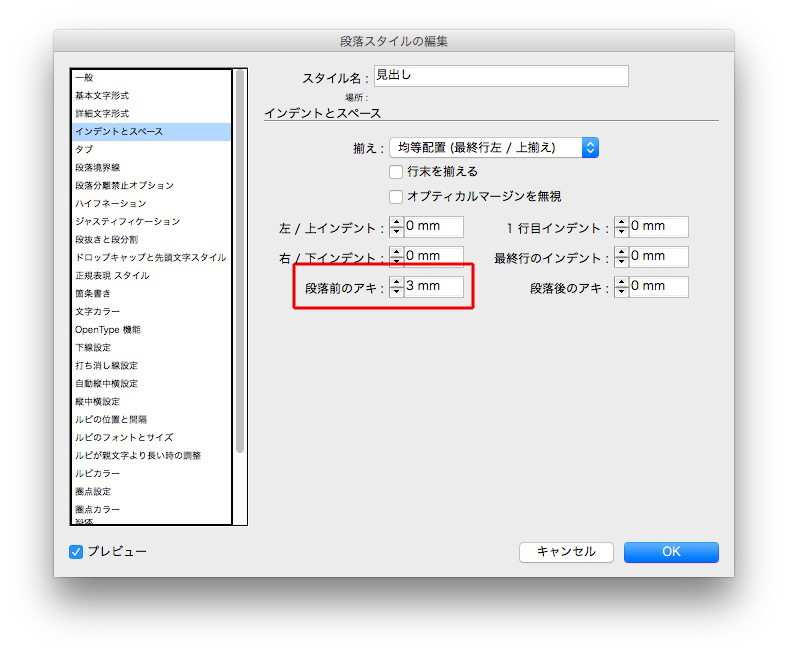
見出しの段落スタイルでは、「先頭文字スタイル」を仕込みます。
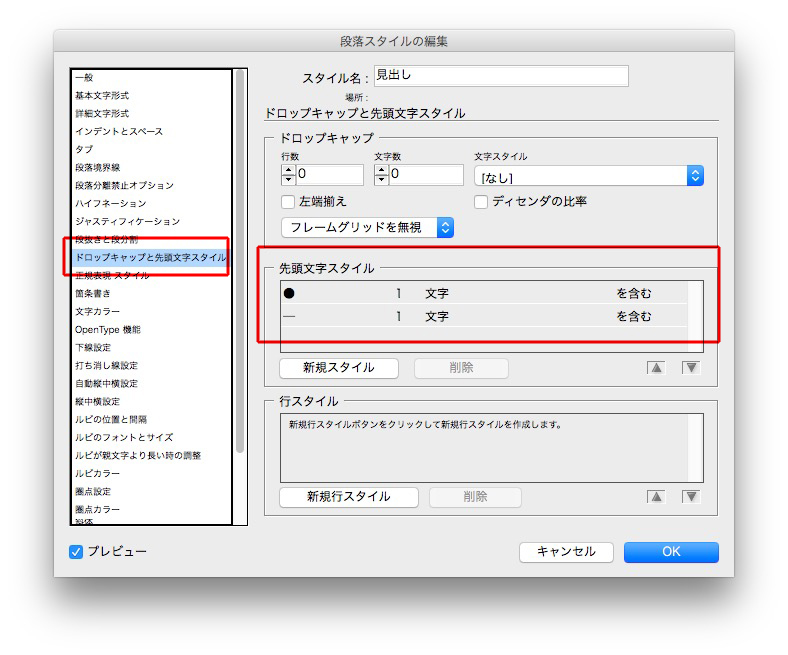
それぞれの文字スタイルは、
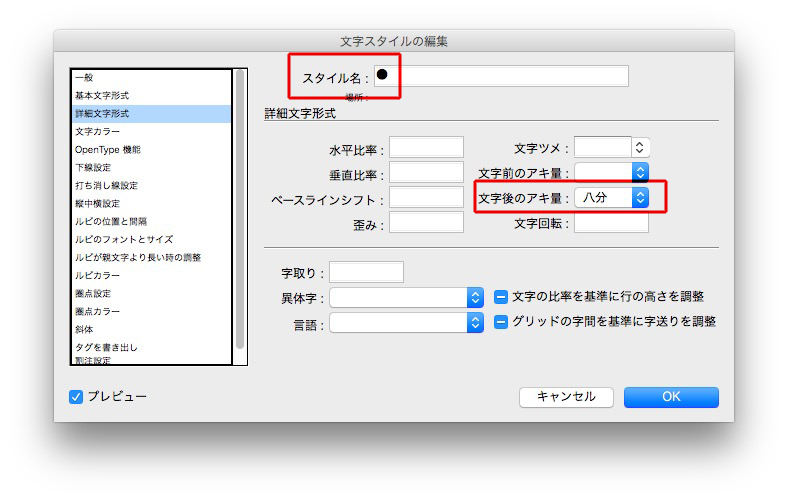
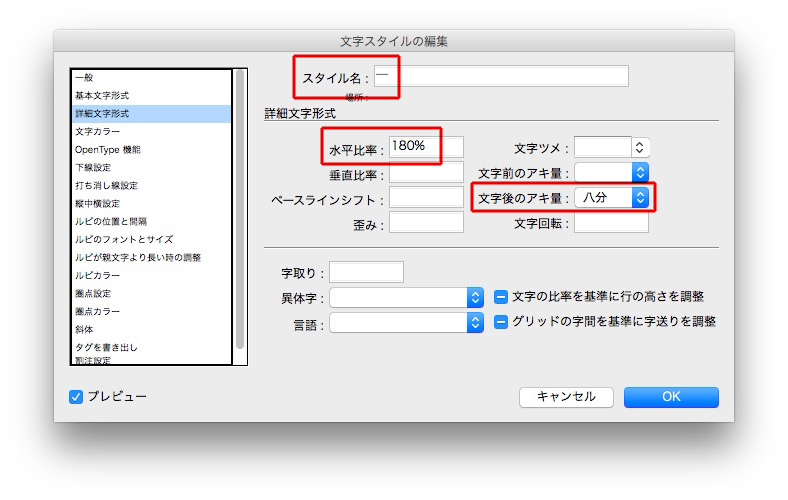
見出しの頭に記号があると、いろいろ遊べます。
記事「《肯定先読み》数字付き見出しの頭に記号をつける方法。」のオマケです。
肯定先読みで、見出しの数字だけに文字スタイルをあてます。
検索文字列 → ^\d{1,}-\d{1,}-\d{1,}(?=●)
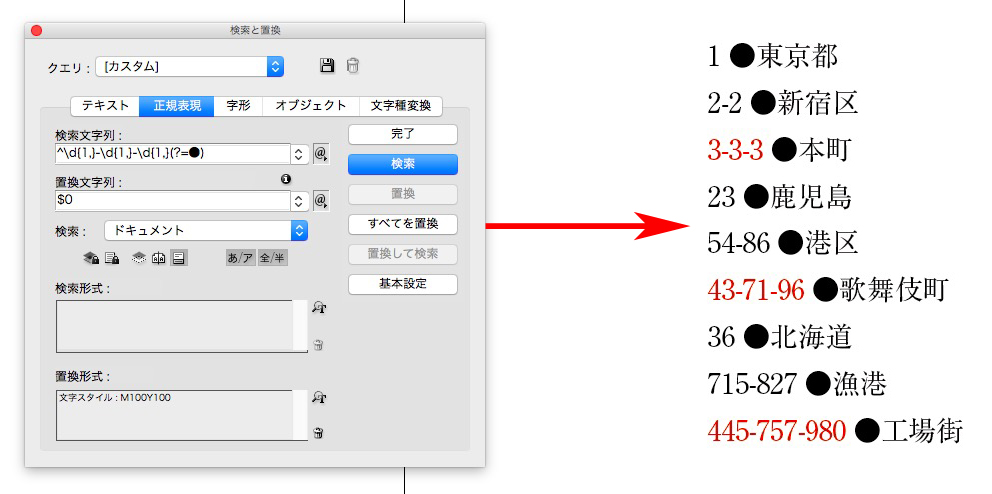
先ほどの文字スタイルを検索して、数字を半角から全角に置換しました。
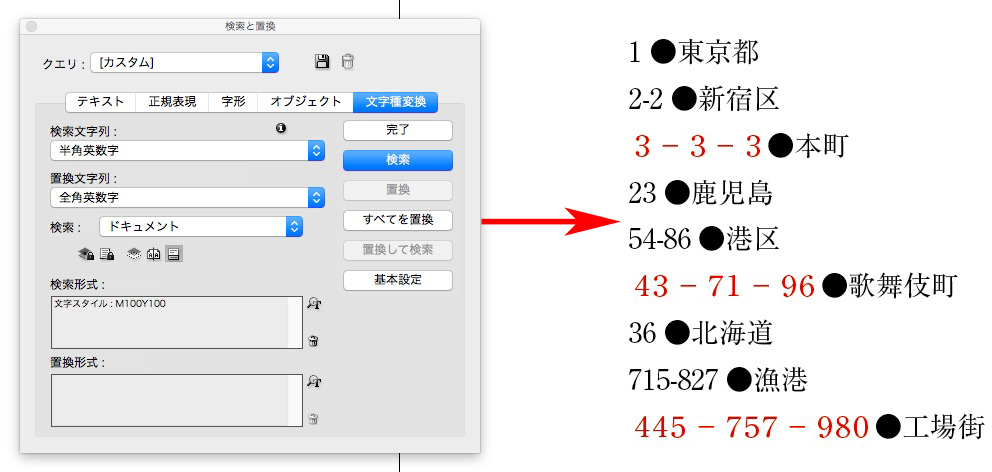
ハイフン付きの数字付き見出し3種類の頭に、それぞれ記号をつけます。

本文中にも●付き数字が出てくるので、肯定先読みを使いました。
検索文字列 → ^\d{1,}(?=●)
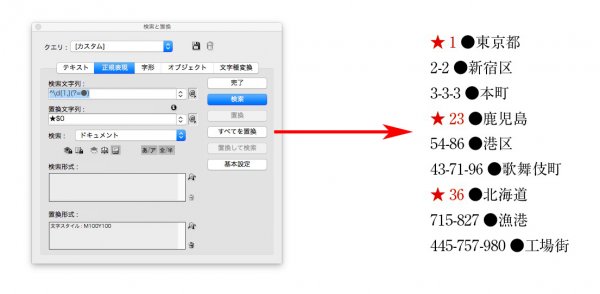
検索文字列 → ^\d{1,}-\d{1,}(?=●)
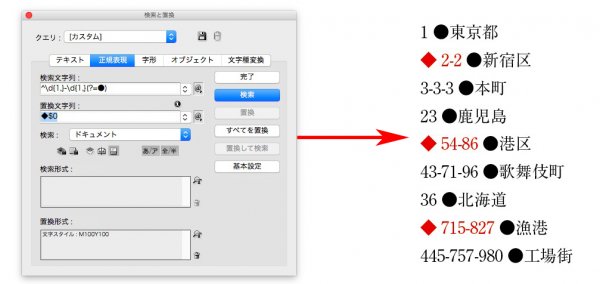
検索文字列 → ^\d{1,}-\d{1,}-\d{1,}(?=●)
肯定先読みのオマケの記事→「《肯定先読み》見出しの数字だけ、半角から全角にする。」
数字付き見出しを検索と置換で、段落スタイルをあてます。
考慮するのは、
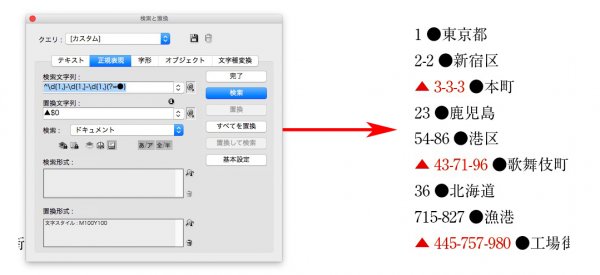
見出しの文字数は、下の青い字です。

①すべてに、標準の段落スタイルをあてます。
検索文字列 → ^\d{1,}●
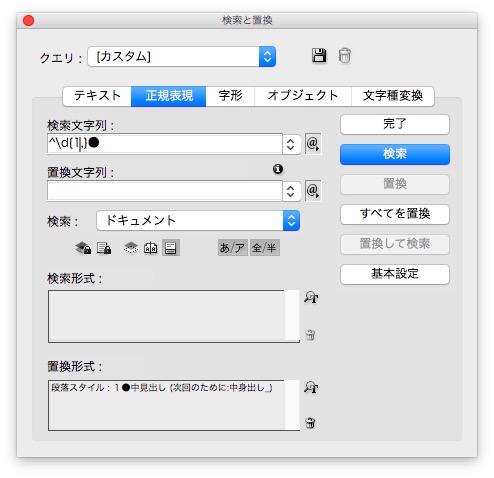
あたりました。

②次に、2行なる26文字以上を選びます。
検索文字列 → ^\d{1,}●.{26,}
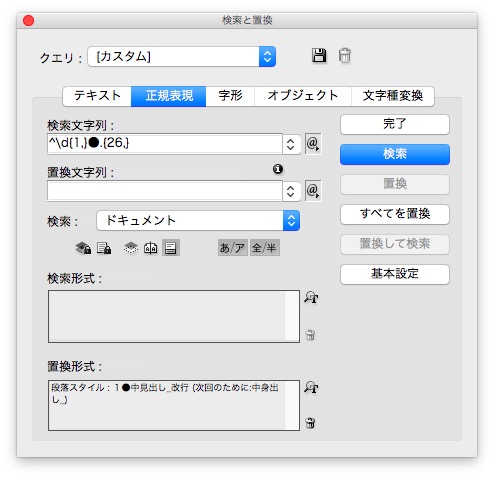
あたりました。

③次に、ふた桁の数字で、25文字以上を選びます。
検索文字列 → ^\d{2,}●.{25,}
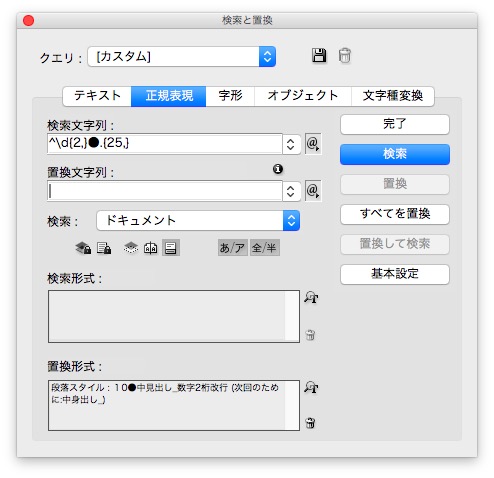
あたりました。

3つ目の数字が二桁以上なら、●の前にタブを入れて、専用の段落スタイルをあてます。
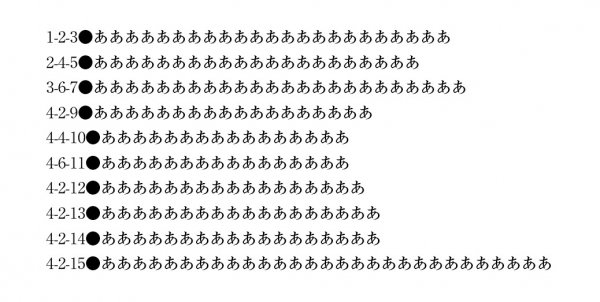
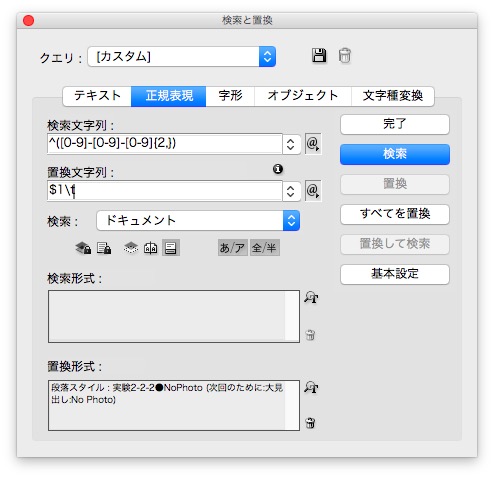
検索文字列 → ^([0-9]-[0-9]-[0-9]{2,})
置換文字列 → $1\t
置換形式 → 段落スタイル
段落スタイルがあたりました。
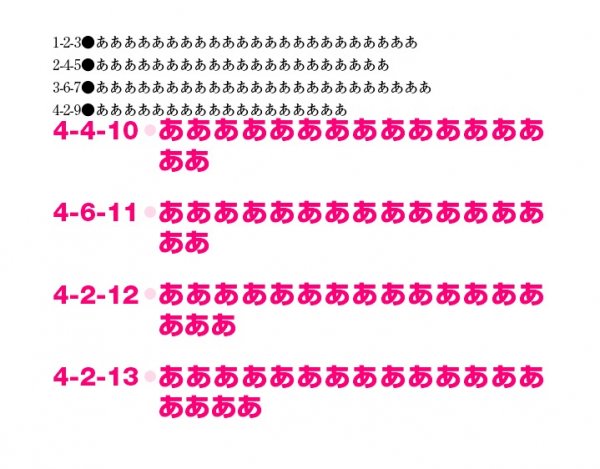
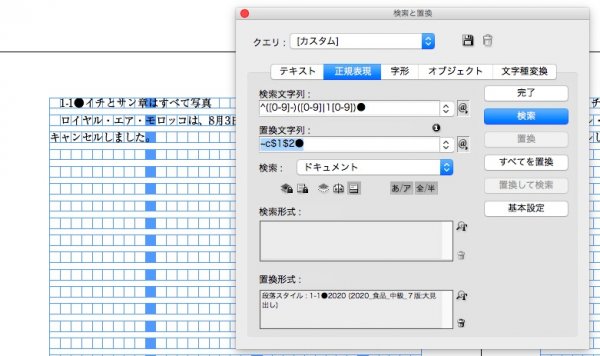
検索文字列 → ^([0-9]-)([0-9]|1[0-9])●
置換文字列 → ~c$1$2●
19までの数字が選ばれました。

検索文字列 → ^[0-9]-[0-9]-([2-9]|1[0-9])
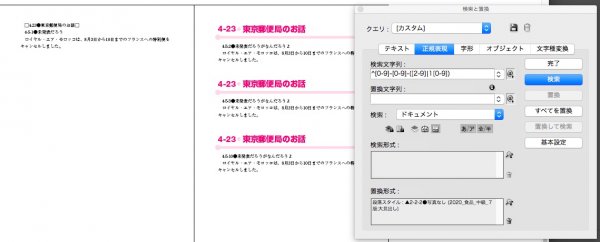
置換されました。
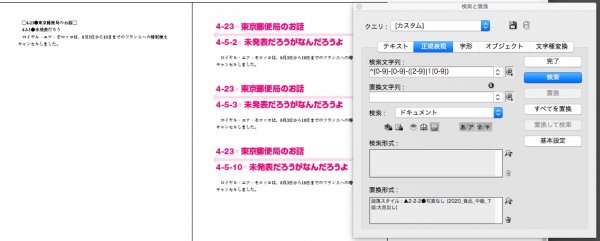
下の行は、3桁目が「1」なので、置換されていません。

参考にしたのは、下の記事です。